DATA A (활성 데이터)에 DATA B (비활성 데이터) 붙이기
PISA에서는 데이터를 학생 인지적 성취 결과 데이터, 학생 설문 데이터, 학교장 설문 데이터, 교사 설문 데이터, 학생 응답 시간 데이터의 5 종류의 데이터를 제공한다. 따라서 이러한 데이터를 합쳐서 새로운 데이터를 만들 필요가 있다. 두 개의 데이터를 합칠 때, SPSS에서는 파일 합치기 함수를 사용한다.
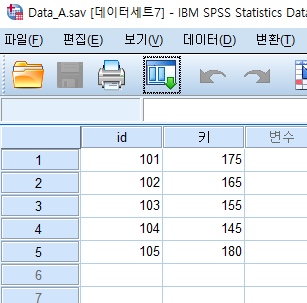
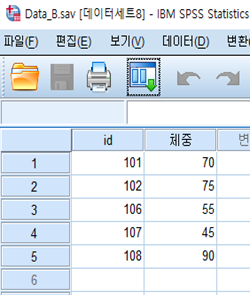
다음과 같은 두 개의 SPSS 데이터, DATA A와 DATA B가 있다. 이때 DATA A에 DATA B를 붙이려고 한다. DATA A가 기준이 되는 데이터, 즉 활성 데이터이고, DATA B는 비활성 데이터이다. 여기서 중요한 점은 DATA A와 DATA B의 id 중에서 다른 id가 있다는 점이다. 이 때, DATA A를 기준으로 DATA B를 붙이기 때문에 DATA B의 id 중에서 DATA A에 없는 id, 즉 106, 107, 108은 DATA A를 기준으로 DATA B를 붙인 새로운 데이터에는 포함되지 않는다.
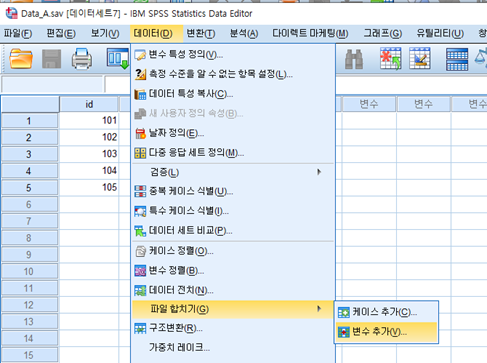
먼저, DATA A와 DATA B를 오름차순으로 정렬을 한다. 그 다음, DATA A에서 [데이터 -> 파일합치기 -> 변수 추가]를 차례로 클릭한다. 그리고 DATA B를 선택하고 계속하기를 클릭한다.
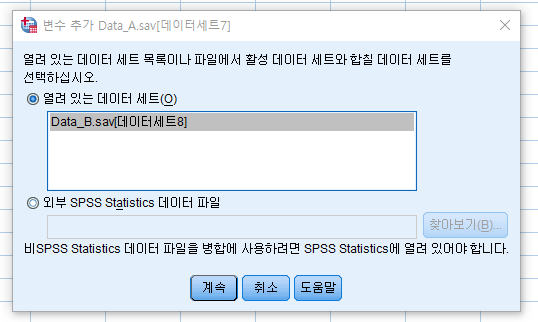
여기서 중요한 것은 비활성 데이터 세트에 기준표 있음을 클릭한다. 즉, DATA A (활성 데이터)에 DATA B (비활성 데이터)의 변수들을 붙이지만, 비활성 데이터 세트에 기준표 있음을 클릭한다.
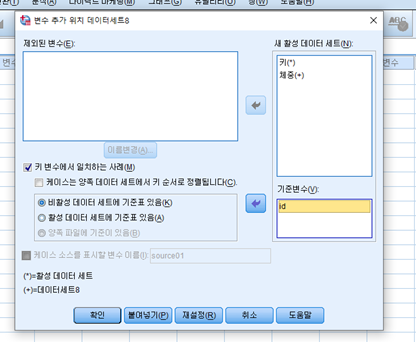
그 결과, 다음과 같은 결과가 나타난다. 이 때, DATA A가 기준이었기 때문에 ID는 DATA A의 ID만 나타난다는 것이다.

활성 데이터(DATA A)에 비활성 데이터(DATA B)를 합칠 때, 활성 데이터(DATA A)의 케이스를 기준으로 할 때, 비활성 데이터 세트에 기준표 있음을 클릭한다는 것이 핵심이다.
DATA A (활성 데이터)와 DATA B (비활성 데이터)의 모든 정보를 포함하여 데이터 합치기
DATA A와 DATA B의 모든 자료를 합치려면 변수 추가에서 ‘케이스는 양쪽 데이터 세트에 키 순서로 정렬됩니다.’를 클릭하면 된다.
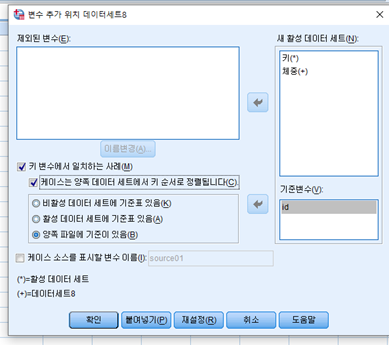
그 결과, 아래와 같이 DATA A와 DATA B가 모든 사례를 포함한 새로운 데이터를 얻을 수 있다.



